





1. Introduction▲
1-1. Avant-propos▲
Boost est un ensemble de bibliothèques portables destinées à faciliter la vie du développeur C++. Boost se propose de construire du code de référence pouvant aussi, à terme, être incorporé au standard (STL).
Pour plus d'informations, vous pouvez consulter :



1-2. But de ce tutoriel▲
Ce tutoriel a pour but de présenter l'utilisation de la bibliothèque Boost.Regex. Ce document est architecturé autour d'un exemple simple de classe C++ permettant d'exploiter et d'utiliser des expressions régulières.
1-3. But des expressions régulières▲
Le but des expressions régulières (certaines littératures parlent aussi d'expressions rationnelles) est de résoudre le problème de l'analyse d'un texte lorsqu'il devient trop complexe pour pouvoir être résolu par analyseur développé "from scratch". Par exemple, savoir si le message de log généré par un serveur Syslog est valide ou non.
Pour rappel, le format d'un message de log Syslog est le suivant :
- La partie PRI : Cette partie est composée de 3, 4 ou 5 caractères. Le premier caractère est le caractère "<" suivi par un nombre représentant la priorité du message et terminé par le caractère ">". La valeur de la priorité est calculée en multipliant la valeur de la facilité du message par 8 et en additionnant la valeur de la sévérité du message.
- La partie HEADER : Cette partie du message Syslog comprend la date du message ainsi que le nom ou l'adresse IP de l'émetteur du message séparés par le caractère espace (" ") et terminée par le caractère espace (" "). La date est au format "Mmm dd hh:mm:ss"
- La partie MSG : Cette partie du message comprend le message texte à transférer.
- Pour plus d'informations sur le protocole Syslog, se référer aux RFC 3164 et RFC 3195.
<165>May 18 14:46:18 192.168.1.1 Un message SyslogLa réalisation d'un analyseur dédié à ce type de message n'est pas triviale, ne serait-ce parce que le nom de l'émetteur du message peut être spécifié par son nom de machine ou bien son adresse IP. Une expression régulière va permettre de résoudre de manière générique cette problématique.
L'expression régulière qui pourrait être utilisée pour cet exemple est la suivante :
<\d{1,3}>(?:Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec) \d\d \d\d:\d\d:\d\d [^ ]* .*Un autre problème qui peut être résolu à l'aide des expressions régulières est l'extraction des données d'un message. Toujours en reprenant l'exemple précédent du message de log Syslog, il peut être parfois intéressant d'extraire les différents champs que sont la priorité du message, la date de génération, le nom ou l'adresse IP de l'émetteur ainsi que le texte du message lui-même.
Dans ce cas-là, on utilisera aussi une expression régulière en utilisant la fonctionnalité de capture de chaînes à l'aide des parenthèses :
<(\d{1,3})>((?:Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec) \d\d \d\d:\d\d:\d\d) ([^ ]*) (.*)Il existe plusieurs manières d'écrire une expression régulière utilisant des syntaxes différentes :
- La syntaxe Perl. C'est la syntaxe utilisée par le langage de programmation Perl.
- La syntaxe POSIX étendue. C'est la syntaxe supportée par l'API C POSIX des expressions régulières et par les utilitaires Unix egrep et awk.
- La syntaxe POSIX basique. C'est la syntaxe utilisée par les utilitaires Unix sed, grep et emacs.
La manière d'écrire une expression régulière et la syntaxe utilisée ne sont pas l'objet de ce tutoriel, il existe d'excellentes ressources sur Internet pour cela :
- Boost.Regex. Le point d'entrée officiel de la documentation (en anglais) de la bibliothèque Boost.Regex sur le site de Boost.
- Regular Expression Syntax. La documentation (en anglais) de la syntaxe des expressions régulières de la bibliothèque Boost.Regex.
- Initiation aux expressions régulières en PHP. Un tutoriel sur les expressions régulières en PHP.
- Utilisation des expressions régulières en .Net. Un tutoriel sur les expressions régulières en .NET.
- Les Expressions Rationnelles appliquées en VBA Access. Un tutoriel sur les expressions régulières en VBA Access.
- Les expressions régulières en C. Un tutoriel sur les expressions régulières en C.
- Les expressions régulières avec l'API Regex de Java. Un tutoriel sur les expressions régulières en JAVA.
Ce tutoriel est organisé en 3 paragraphes :
- Le paragraphe 2 traite l'installation, la configuration et la compilation de Boost.
- Le paragraphe 3 concerne la spécification de la classe C++ CMyRegex permettant de manipuler des expressions régulières en encapsulant un objet Boost.Regex.
- Le paragraphe 4 décrit un programme de test permettant de valider cette classe C++ et de la tester.
1-4. Environnement de développement▲
L'environnement de développement utilisé lors de la rédaction de ce tutoriel est le suivant :
| Architecture cible | Microprocesseur x86 | Mon poste de travail est un x86 |
| Plateforme cible | Microsoft Windows | C'est la plateforme de développement que j'utilise tous les jours. Ce choix signifie que les fonctions natives de l'API WIN32 seront de préférence utilisées. |
| Environnement de développement | Visual Studio 2005 | C'est l'environnement de développement que j'utilise de manière professionnelle |
| Langage de développement | C++ | La bibliothèque Boost ne peut s'utiliser que dans un environnement C++ |
| Version de Boost | 1.38.0 | C'est la version courante à la date d'écriture de ce tutoriel |
| Jeux de caractères supportés | Support des jeux de caractères Unicode et ANSI | Nativement, les std::wstring sont utilisées par la classe CMyRegex de ce tutoriel. Pour des raisons de compatibilité et aussi d'utilisabilité de la classe, les chaînes de caractères ANSI (std::string) sont aussi supportées. Elles sont transformées en interne en sdt:wstring avant d'être utilisées. |
1-5. Remerciements▲
Je tiens à remercier 3DArchi, Jean-Marc.Bourguet, Luc Hermitte, Alp et Florian Goo pour leurs conseils avisés lors de la relecture de ce tutoriel.
2. Installation de Boost▲
2-1. Téléchargement▲
La première chose à faire est de créer le répertoire d'installation de Boost. Par choix personnel et arbitraire, celui-ci s'appellera boost sera créé dans le répertoire C:\Program Files\.
La seconde chose à faire est de récupérer l'archive complète de Boost. Cette archive se récupère à partir du site de Boost. En fait, cette archive est hébergée sur le site sourceforge, le fichier récupéré est au format zip (plus par habitude de ce format que par véritable raison). Le fichier téléchargé boost_1_38_0.zip est sauvegardé dans le répertoire C:\Program Files\boost\. La taille de ce fichier est de 56 142 848 octets.
La troisième chose à faire est de télécharger l'utilitaire bjam qui est l'utilitaire nécessaire à la compilation de Boost. Cet utilitaire se récupère aussi à partir du site de Boost. Cet utilitaire est aussi hébergé sur le site sourceforge, le fichier récupéré est boost-jam-3.1.17-1-ntx86.zip. Il permet de compiler le paquetage de Boost sur une architecture de type PC x86. Pour les autres architectures, il conviendra de télécharger la version correspondante de l'utilitaire bjam. Le fichier téléchargé boost-jam-3.1.17-1-ntx86.zip est aussi sauvegardé dans le répertoire C:\Program Files\boost\. La taille de ce fichier est de 117 793 octets.
Récapitulatif :
- Création du répertoire C:\Program Files\boost\
- Téléchargement de l'archive Boost 1.38.0 et copie dans le répertoire C:\Program Files\boost\
- Téléchargement de l'utilitaire bjam 3.1.17.1 pour architecture i386 et copie dans le répertoire C:\Program Files\boost\
2-2. Décompression▲
Une fois que le téléchargement de ces 2 fichiers est terminé, il reste à décompresser ces 2 archives.
On commence par décompresser le fichier boost_1_38_0.zip et l'on met tous les fichiers et répertoires contenus dans l'archive sous le répertoire C:\Program Files\boost\boost_1_38_0\. La structure décompressée présente cette forme :
C:\program Files\boost\boost_1_38_0\ .................The “Boost root directory”
index.htm .........A copy of www.boost.org starts here
boost\ .........................All Boost Header files
lib\ .....................precompiled library binaries
libs\ ............Tests, .cpps, docs, etc., by library
index.html ........Library documentation starts here
algorithm\
any\
array\
…more libraries…
status\ .........................Boost-wide test suite
tools\ ...........Utilities, e.g. bjam, quickbook, bcp
more\ ..........................Policy documents, etc.
doc\ ...............A subset of all Boost library docsEnsuite, on extraira le fichier bjam.exe de l'archive boost-jam-3.1.17-1-ntx86.zip et il sera copié dans le répertoire C:\Program Files\boost\boost_1_38_0\.
Récapitulatif :
- Décompression de Boost dans le répertoire C:\Program Files\boost\
- Décompression de bjam.exe et copie du fichier dans le répertoire C:\program Files\boost\boost_1_38_0\
2-3. Compilation▲
Boost contient 2 types de bibliothèques :
- les bibliothèques Header only, ces bibliothèques ne nécessitent pas de compilation préalable, tout est contenu dans les en-têtes et elles sont prêtes à être utilisées immédiatement.
- les bibliothèques qui nécessitent une compilation initiale.
Les bibliothèques qui nécessitent une compilation initiale avant leur utilisation sont :
- Boost.Filesystem
- Boost.IOStreams
- Boost.ProgramOptions
- Boost.Python
- Boost.Regex
- Boost.Serialization
- Boost.Signals
- Boost.Thread
- Boost.Wave
Comme le but de ce tutoriel est d'utiliser Boost.Regex, il va donc falloir compiler les bibliothèques pour cela, les commandes à effectuer sont les suivantes :
- Lancer un shell. Pour cela, faire menu Démarrer/Exécuter puis taper la commande cmd
- Se positionner dans le répertoire de Boost. Pour cela, taper la commande cd "C:\program Files\boost\boost_1_38_0\" dans le shell précédemment lancé. Attention aux guillemets dans la commande, ils sont importants.
- Initialiser l'environnement Visual Studio 2005. Pour cela, taper la commande "C:\Program Files\Microsoft Visual Studio 8\VC\vcvarsall.bat" x86 dans le shell précédemment lancé. Cette commande suppose que Visual Studio est installé dans le répertoire C:\Program Files\Microsoft Visual Studio 8\ qui est le répertoire d'installation par défaut. Attention aux guillemets dans la commande, ils sont importants.
- Lancer la compilation. Pour cela taper la commande bjam --toolset=msvc-8.0 --build-type=complete stage
Les options passées à bjam sont les suivantes :
| Option | Explication |
|---|---|
| --toolset=msvc-8.0 | Cette option indique à bjam que le compilateur utilisé est le compilateur Microsoft (version 8.0). Les compilateurs supportés sont : Hewlett Packard (acc), Borland (borland), Comeau Computing (como), Metrowerks/FreeScale (cw), Digital Mars (dmc), Apple Computer (darwin), The Gnu Project (gcc), Hewlett Packard (hp_cxx), Intel (intel), Borland (kylix), Microsoft (msvc), QNX Software Systems (qcc), Sun (sun) et IBM (vacpp). |
| --build-type=complete | Cette option force bjam à construire toutes les variantes des bibliothèques. |
| stage | Cette option indique à bjam le nom du répertoire dans lequel placer les bibliothèques construites. Dans ce tutoriel, les bibliothèques sont placées dans le répertoire C:\Program Files\boost\boost_1_38_0\stage\lib\. |
La compilation peut être longue, soyez donc patients... (2 heures de compilation sur mon PC)
2-4. Configuration de Visual Studio 2005▲
La dernière étape consiste à configurer Visual Studio afin qu'il sache dans quels répertoires aller chercher les fichiers d'en-tête et les bibliothèques. Pour cela, il faut lancer Visual Studio 2005, aller dans le menu Outils/Options... et modifier les chemins de recherche comme spécifié sur les deux copies d'écran suivantes :
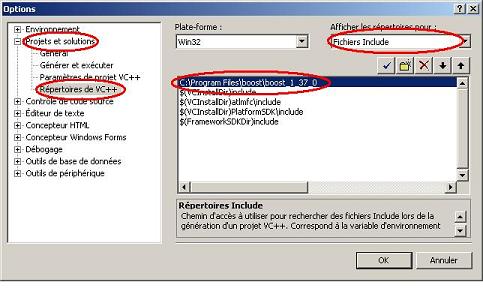 Ajout du chemin C:\Program Files\boost\boost_1_38_0\ de recherche des fichiers d'en-tête |
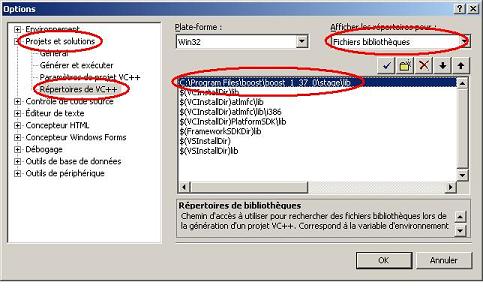 Ajout du chemin C:\Program Files\boost\boost_1_38_0\stage\lib\ de recherche des bibliothèques |
Il est important que les chemins de Boost soient mis en premier dans la liste des répertoires à rechercher.
3. La classe CMyRegex▲
Ce paragraphe décrit la classe C++ CMyRegex. Il comprend la description des méthodes de la classe ainsi que le code de cette classe.
Rappel : La classe C++ CMyRegex présentée dans ce tutoriel est un exemple d'implémentation. Son but est de manipuler des expressions régulières tout en encapsulant un objet Boost.Regex. L'interface de cette classe peut ne pas être adaptée à votre besoin. Dans ce cas, il faudra probablement réécrire votre propre classe en reprenant les quelques concepts montrés ici.
3-1. Fonctionnement général de la classe▲
Le fonctionnement général de la classe est le suivant :
- Chaque fonction retourne un booléen indiquant si la fonction s'est déroulée correctement ou non.
- Aucune exception n'est levée par la classe. Les exceptions levées par la bibliothèque Boost.Regex sont attrapées et traitées par les différentes fonctions.
- En cas d'erreur, il est possible d'appeler la fonction GetLastError() de la classe pour obtenir plus d'information sur l'erreur.
- Les différentes fonctions attendent des paramètres sous la forme d'une string UNICODE (std::wstring) ou bien d'une ANSI (std::string).
- La forme préférée et optimisée est std::wstring. Pour les string ANSI (std::string), elles sont transformées en interne par la classe en string UNICODE (std::wstring).
- Pour créer une instance de classe, le constructeur peut être appelé en fournissant comme paramètre une expression régulière valide.
- Il est toutefois possible de créer l'instance sans fournir d'expression régulière. Cette expression régulière devra alors être fournie ultérieurement par un appel à la fonction SetRegex().
- Une fois que l'expression régulière est assignée à l'instance de la classe, il est possible de tester des chaînes de caractères avec cette expression régulière. Pour ce faire, c'est la fonction Match() qui doit être appelée.
- La fonction Match() possède 2 formes surchargées. La première forme teste uniquement si la chaîne de caractères passée en paramètre correspond à l'expression régulière de l'instance de la classe.
- La seconde forme de la fonction Match() teste aussi si la chaîne de caractères passée en paramètre correspond à l'expression régulière de l'instance de la classe mais en plus, elle retourne les sous-chaînes extraites par les parenthèses de l'expression régulière.
- Si par exemple, une expression régulière contient 2 blocs de parenthèses, le tableau retourné contiendra alors 3 chaînes de caractères. La chaîne complète (indice 0 du tableau retourné), la chaîne de caractères correspondant au premier bloc de parenthèses (indice 1 du tableau retourné) et la chaîne de caractères correspondant au second bloc de parenthèses (indice 2 du tableau retourné).
- La syntaxe des expressions régulières utilisées est la syntaxe POSIX étendue.
3-2. Les méthodes et membres de la classe▲
3-1-1. Les fonctions de base de la classe▲
| Nom | Visibilité | Rôle |
|---|---|---|
| CMyRegex(void) | publique | Le constructeur de la classe. Aucune expression régulière n'est assignée à l'instance de la classe. |
| explicit CMyRegex(const std::wstring & Regex) | publique | Le constructeur explicite de la classe. Le paramètre est l'expression régulière à utiliser, il s'agit d'une string UNICODE. |
| explicit CMyRegex(const std::string & Regex) | publique | Le constructeur explicite de la classe. Le paramètre est l'expression régulière à utiliser, il s'agit d'une string ANSI. |
| void Reset(void) | publique | Cette fonction permet de réinitialiser l'instance de la classe. |
3-1-2. Les fonctions de manipulation de l'expression régulière▲
| Nom | Visibilité | Rôle |
|---|---|---|
| bool SetRegex(const std::wstring & Regex) | publique | Cette fonction permet de positionner une expression régulière. Le paramètre est l'expression régulière à utiliser, il s'agit d'une string UNICODE. |
| bool SetRegex(const std::string & Regex) | publique | Cette fonction permet de positionner une expression régulière. Le paramètre est l'expression régulière à utiliser, il s'agit d'une string ANSI. |
| const std::wstring & GetRegex(void) const | publique | Cette fonction permet de récupérer l'expression régulière de l'instance de la classe. |
| std::wstring m_regex_str | privée | Cette variable contient l'expression régulière de l'instance de la classe. |
3-1-3. Les fonctions de manipulation de la dernière erreur▲
| Nom | Visibilité | Rôle |
|---|---|---|
| void set_last_error(const CMyRegexError_t Code, const std::string & MoreInfo = "") | privée | Cette fonction permet de positionner le code de la dernière erreur survenue dans l'instance de la classe ainsi qu'éventuellement un complément d'information sur l'erreur. |
| const std::wstring GetLastError(void) const | publique | Cette fonction permet de récupérer le texte de la dernière erreur survenue dans l'instance de la classe. |
| CMyRegexError_t m_last_error | privée | Cette variable contient le code de la dernière erreur survenue dans l'instance de la classe. |
| std::wstring m_last_error_moreinfo | privée | Cette variable contient un éventuel complément d'information sur l'erreur. |
3-1-4. Les fonctions de matching d'expression▲
| Nom | Visibilité | Rôle |
|---|---|---|
| bool Match(const std::wstring & Expression) | publique | Cette fonction permet de vérifier si l'expression passée en paramètre sous la forme d'une string UNICODE correspond à l'expression régulière de l'instance de la classe. |
| bool Match(const std::string & Expression) | publique | Cette fonction permet de vérifier si l'expression passée en paramètre sous la forme d'une string ANSI correspond à l'expression régulière de l'instance de la classe. |
| bool Match(const std::wstring & Expression, std::vector<std::wstring> & ArrayValue) | publique | Cette fonction permet de vérifier si l'expression passée en paramètre sous la forme d'une string UNICODE correspond à l'expression régulière de l'instance de la classe. Si oui, les éventuelles sous-chaînes sont retournées dans le tableau passé en paramètre. Le tableau passé en paramètre est réinitialisé lors de l'appel à la fonction. |
| bool Match(const std::string & Expression, std::vector<std::wstring> & ArrayValue) | publique | Cette fonction permet de vérifier si l'expression passée en paramètre sous la forme d'une string ANSI correspond à l'expression régulière de l'instance de la classe. Si oui, les éventuelles sous chaînes sont retournées dans le tableau passé en paramètre. Le tableau passé en paramètre est réinitialisé lors de l'appel à la fonction. |
3-1-5. Les autres fonctions▲
| Nom | Visibilité | Rôle |
|---|---|---|
| bool translate(const std::string & AString, std::wstring & WString) | privée | Cette fonction permet de transformer une string ANSI en string UNICODE. |
3-3. Le fichier header▲
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
61.
62.
63.
64.
65.
66.
67.
68.
69.
70.
71.
72.
#ifndef MyRegex_INCLUDED
#define MyRegex_INCLUDED
#include <string>
#include <vector>
#include <boost/regex.hpp>
class CMyRegex
{
public:
typedef enum
{ CMyRegex_NoError,
CMyRegex_InvalidRegex,
CMyRegex_EmptyRegex,
CMyRegex_NoMatch,
CMyRegex_TranslateError,
CMyRegex_MemoryError,
CMyRegex_SettingError,
} CMyRegexError_t;
// The constructor with no string
inline CMyRegex(void) { }
// The explicit constructor with a ANSI string
inline explicit CMyRegex(const std::string & Regex) { SetRegex(Regex); }
// The explicit constructor with a UNICODE string
inline explicit CMyRegex(const std::wstring & Regex) { SetRegex(Regex); }
// Reset all parameter of the class
void Reset(void);
// The functions to manipulate the regular expression
bool SetRegex(const std::string & Regex);
bool SetRegex(const std::wstring & Regex);
inline const std::wstring & GetRegex(void) const { return m_regex_str; }
// The functions to check a string with the current regular expression
bool Match(const std::string & Expression);
bool Match(const std::wstring & Expression);
// The functions to check a string with the current regular expression.
// This set of function return the sub string
bool Match(const std::string & Expression, std::vector<std::wstring> & ArrayValue);
bool Match(const std::wstring & Expression, std::vector<std::wstring> & ArrayValue);
// The function to get the last error message
const std::wstring GetLastError(void) const;
private:
// The function to translate a ANSI string into a UNICODE string
bool translate(const std::string & AString, std::wstring & WString);
// The functions to set the last error message
void set_last_error(const CMyRegexError_t Code, const std::string & MoreInfo = "");
//
// The members
// -----------
// The current regular expression
std::wstring m_regex_str;
// The boost regex object used to match
boost::wregex m_regex_obj;
// The last error message
CMyRegexError_t m_last_error;
std::wstring m_last_error_moreinfo;
};
#endif // #ifndef MyRegex_INCLUDED
3-4. Le fichier source▲
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
61.
62.
63.
64.
65.
66.
67.
68.
69.
70.
71.
72.
73.
74.
75.
76.
77.
78.
79.
80.
81.
82.
83.
84.
85.
86.
87.
88.
89.
90.
91.
92.
93.
94.
95.
96.
97.
98.
99.
100.
101.
102.
103.
104.
105.
106.
107.
108.
109.
110.
111.
112.
113.
114.
115.
116.
117.
118.
119.
120.
121.
122.
123.
124.
125.
126.
127.
128.
129.
130.
131.
132.
133.
134.
135.
136.
137.
138.
139.
140.
141.
142.
143.
144.
145.
146.
147.
148.
149.
150.
151.
152.
153.
154.
155.
156.
157.
158.
159.
160.
161.
162.
163.
164.
165.
166.
167.
168.
169.
170.
171.
172.
173.
174.
175.
176.
177.
178.
179.
180.
181.
182.
183.
184.
185.
186.
187.
188.
189.
190.
191.
192.
193.
194.
195.
196.
197.
198.
199.
200.
201.
202.
203.
204.
205.
206.
207.
208.
209.
210.
211.
212.
213.
214.
215.
216.
217.
218.
219.
220.
221.
222.
223.
224.
225.
226.
227.
228.
229.
230.
231.
232.
233.
234.
#include "MyRegex.h"
#include <Windows.h>
// Reset all parameter of the class
void CMyRegex::Reset(void)
{
SetRegex(L"");
set_last_error(CMyRegex_NoError);
}
// Set the regular expression with a ANSI string
bool CMyRegex::SetRegex(const std::string & Regex)
{
// translate the ANSI string into a UNICODE string
std::wstring str;
if(translate(Regex, str) == false)
{
// An error while translating
return false;
}
// Set the regular expression (with a UNICODE string)
return SetRegex(str);
}
// Set the regular expression with a UNICODE string
bool CMyRegex::SetRegex(const std::wstring & Regex)
{
try
{
// Try to set the regular expression
m_regex_obj.assign(Regex, boost::regex_constants::extended);
// Save the regular expression
m_regex_str = Regex;
return true;
}
catch(const std::exception & e)
{
// An error while setting the regular expression
set_last_error(CMyRegex_InvalidRegex, e.what());
m_regex_str = L"";
return false;
}
}
// Match a ANSI string against the current regular expression
bool CMyRegex::Match(const std::string & Expression)
{
// translate the ANSI string into a UNICODE string
std::wstring str;
if(translate(Expression, str) == false)
{
// Translate error
return false;
}
// Match the string
return Match(str);
}
// Match a UNICODE string against the current regular expression
bool CMyRegex::Match(const std::wstring & Expression)
{
// Check if a regex is set
if(GetRegex().length() == 0)
{
// The regex is not set
set_last_error(CMyRegex_EmptyRegex);
return false;
}
try
{
// Match the string against the current regular expression
if(regex_match(Expression, m_regex_obj) == false)
{
// The expression does not match the regex
set_last_error(CMyRegex_NoMatch);
return false;
}
return true;
}
catch(const std::exception & e)
{
// An exception, it is probably an error
set_last_error(CMyRegex_NoMatch, e.what());
return false;
}
}
// Match a ANSI string against the current regular expression
bool CMyRegex::Match(const std::string & Expression, std::vector<std::wstring> & ArrayValue)
{
// translate the ANSI string into a UNICODE string
std::wstring str;
if(translate(Expression, str) == false)
{
// Translate error
return false;
}
// Match the string
return Match(str, ArrayValue);
}
// Match a UNICODE string against the current regular expression
bool CMyRegex::Match(const std::wstring & Expression, std::vector<std::wstring> & ArrayValue)
{
// Empty the array of values
ArrayValue.clear();
// Check if a regex is set
if(GetRegex().length() == 0)
{
// The regex is not set
set_last_error(CMyRegex_EmptyRegex);
return false;
}
try
{
// Match the string against the current regular expression
boost::wsmatch what;
if(regex_match(Expression, what, m_regex_obj) == false)
{
// The expression does not match the regex
set_last_error(CMyRegex_NoMatch);
return false;
}
// Read all values
for(unsigned int boucle = 0; boucle != what.size(); boucle++)
{
// Make a temporary string
std::wstring str;
str.assign(what[boucle].first, what[boucle].second);
// Add the temporary string into the array
ArrayValue.push_back(str);
}
return true;
}
catch(const std::exception & e)
{
// An exception, it is probably an error
set_last_error(CMyRegex_NoMatch, e.what());
return false;
}
}
// translate a ANSI string into a UNICODE string
bool CMyRegex::translate(const std::string & AString, std::wstring & WString)
{
// Try to translate the string (1st try)
wchar_t buffer[1024];
int ret = ::MultiByteToWideChar(CP_ACP, 0, AString.c_str(), -1, buffer, sizeof(buffer) / sizeof(buffer[0]));
if(ret != 0)
{
// The translate is correct
WString = buffer;
return true;
}
// Test the error to check if the buffer is big enougth
if(::GetLastError() != ERROR_INSUFFICIENT_BUFFER)
{
set_last_error(CMyRegex_TranslateError);
return false;
}
// Ask the needed size to translate the string
ret = ::MultiByteToWideChar(CP_ACP, 0, AString.c_str(), -1, NULL, 0);
if(ret == 0)
{
// An error while translating
set_last_error(CMyRegex_TranslateError);
return false;
}
// Allocate a buffer large enougth and store it in a boost::scoped_array object
boost::scoped_array<wchar_t> p_buf(new wchar_t [ret]);
if(p_buf.get() == NULL)
{
// A memory allocation error
set_last_error(CMyRegex_MemoryError);
return false;
}
// Perform the translate (2nd try)
ret = ::MultiByteToWideChar(CP_ACP, 0, AString.c_str(), -1, p_buf.get(), ret);
if(ret == 0)
{
// An error while translating
set_last_error(CMyRegex_TranslateError);
return false;
}
// The translate is correct
WString = p_buf.get();
return true;
}
// Set the last error
void CMyRegex::set_last_error(const CMyRegexError_t Code, const std::string & MoreInfo /*= ""*/)
{
// save the last error code
m_last_error = Code;
// Translate the information into a UNICODE string
translate(MoreInfo, m_last_error_moreinfo);
}
const std::wstring CMyRegex::GetLastError(void) const
{
std::wstring ret;
switch(m_last_error)
{
default : ret = L"Unknown error"; break;
case CMyRegex_NoError : ret = L"No error"; break;
case CMyRegex_InvalidRegex : ret = L"Invalid regular expression"; break;
case CMyRegex_EmptyRegex : ret = L"Regular expression is empty"; break;
case CMyRegex_NoMatch : ret = L"Expression does not match with the regular expression"; break;
case CMyRegex_TranslateError : ret = L"Error while translating an ANSI string to a UNICODE string"; break;
case CMyRegex_MemoryError : ret = L"Memory allocation error"; break;
case CMyRegex_SettingError : ret = L"Error while setting the error code"; break;
}
// add the more info string if not empty
if(m_last_error_moreinfo.length() != 0)
ret += L" (" + m_last_error_moreinfo + L")";
return ret;
}
4. Le test de la classe CMyRegex▲
Le code présenté dans ce paragraphe permet de valider le fonctionnement de la classe CMyRegex. Ce code repose uniquement sur la fonction wmain() qui enchaine les différents tests et sur la fonction check() qui affiche les résultats de chacun de ces tests.
4-1. Le fichier source de test de la classe CMyRegex▲
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
61.
62.
63.
64.
65.
66.
67.
68.
69.
70.
71.
72.
73.
74.
75.
76.
77.
78.
79.
80.
81.
82.
83.
84.
85.
86.
87.
88.
89.
90.
91.
92.
93.
94.
95.
96.
97.
98.
99.
100.
101.
102.
103.
104.
105.
#include "MyRegex.h"
#include <iostream>
void check(const std::wstring & TestName, const CMyRegex & Regex, const std::vector<std::wstring> & Array, const bool ret)
{
// display the test name
std::wcout << TestName << L" : ";
if(ret == false)
{
// display the error string and leave the function
std::wcout << L"Echec - " << Regex.GetLastError() << std::endl;
return;
}
// display OK
std::wcout << L"OK" << std::endl;
// display the string returned in the array (if any)
for(size_t boucle = 0; boucle != Array.size(); boucle++)
{
std::wcout << L"\tArray[" << boucle << L"] = " << Array[boucle] << std::endl;
}
}
int wmain(void)
{
// the variables
std::vector<std::wstring> val;
CMyRegex regex;
// the tests
check(L"Regex ANSI invalide ", regex, val, regex.SetRegex("(t(o).*"));
check(L"Regex UNICODE invalide", regex, val, regex.SetRegex(L"t)(o).*"));
check(L"Regex ANSI valide ", regex, val, regex.SetRegex("(t)(o).*"));
check(L"Regex UNICODE valide ", regex, val, regex.SetRegex(L"(t)(o).*"));
check(L"ANSI match pas ", regex, val, regex.Match("otototototo"));
check(L"UNICODE match pas ", regex, val, regex.Match(L"otototototo"));
check(L"ANSI match ", regex, val, regex.Match("tototototo"));
check(L"UNICODE match ", regex, val, regex.Match(L"tototototo"));
check(L"ANSI match pas ", regex, val, regex.Match("otototototo", val));
check(L"UNICODE match pas ", regex, val, regex.Match(L"otototototo", val));
check(L"ANSI match ", regex, val, regex.Match("tototototo", val));
check(L"UNICODE match ", regex, val, regex.Match(L"tototototo", val));
// test avec chaine vide
check(L"chaine ANSI vide ", regex, val, regex.Match(L""));
check(L"chaine UNICODE vide ", regex, val, regex.Match(""));
check(L"chaine ANSI vide ", regex, val, regex.Match(L"", val));
check(L"chaine UNICODE vide ", regex, val, regex.Match("", val));
// expression régulière vide
regex.Reset();
check(L"chaine ANSI vide ", regex, val, regex.Match(L""));
check(L"chaine UNICODE vide ", regex, val, regex.Match(""));
check(L"chaine ANSI vide ", regex, val, regex.Match(L"", val));
check(L"chaine UNICODE vide ", regex, val, regex.Match("", val));
// Construction par copie
regex.SetRegex(L"(t)(o).*");
{
CMyRegex regex2(regex);
check(L"ANSI match ", regex2, val, regex2.Match("tototototo"));
check(L"UNICODE match ", regex2, val, regex2.Match(L"tototototo"));
check(L"ANSI match pas ", regex2, val, regex2.Match("otototototo"));
check(L"UNICODE match pas ", regex2, val, regex2.Match(L"otototototo"));
}
// Construction par affectation
{
CMyRegex regex2;
regex2 = regex;
check(L"ANSI match ", regex2, val, regex2.Match("tototototo"));
check(L"UNICODE match ", regex2, val, regex2.Match(L"tototototo"));
check(L"ANSI match pas ", regex2, val, regex2.Match("otototototo"));
check(L"UNICODE match pas ", regex2, val, regex2.Match(L"otototototo"));
}
// utilisation du constructeur explicit ANSI
{
CMyRegex regex2("(t)(o).*");
check(L"ANSI match ", regex2, val, regex2.Match("tototototo"));
check(L"UNICODE match ", regex2, val, regex2.Match(L"tototototo"));
check(L"ANSI match pas ", regex2, val, regex2.Match("otototototo"));
check(L"UNICODE match pas ", regex2, val, regex2.Match(L"otototototo"));
}
// utilisation du constructeur explicit UNICODE
{
CMyRegex regex2(L"(t)(o).*");
check(L"ANSI match ", regex2, val, regex2.Match("tototototo"));
check(L"UNICODE match ", regex2, val, regex2.Match(L"tototototo"));
check(L"ANSI match pas ", regex2, val, regex2.Match("otototototo"));
check(L"UNICODE match pas ", regex2, val, regex2.Match(L"otototototo"));
}
return 0;
}
4-2. Résultat attendu des tests de la classe CMyRegex▲
Le résultat attendu dans la console est le suivant :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
Regex ANSI invalide : Echec - Invalid regular expression (Unmatched ( or \()
Regex UNICODE invalide : Echec - Invalid regular expression (Unmatched ( or \()
Regex ANSI valide : OK
Regex UNICODE valide : OK
ANSI match pas : Echec - Expression does not match with the regular expression
UNICODE match pas : Echec - Expression does not match with the regular expression
ANSI match : OK
UNICODE match : OK
ANSI match pas : Echec - Expression does not match with the regular expression
UNICODE match pas : Echec - Expression does not match with the regular expression
ANSI match : OK
Array[0] = tototototo
Array[1] = t
Array[2] = o
UNICODE match : OK
Array[0] = tototototo
Array[1] = t
Array[2] = o
chaine ANSI vide : Echec - Expression does not match with the regular expression
chaine UNICODE vide : Echec - Expression does not match with the regular expression
chaine ANSI vide : Echec - Expression does not match with the regular expression
chaine UNICODE vide : Echec - Expression does not match with the regular expression
chaine ANSI vide : Echec - Regular expression is empty
chaine UNICODE vide : Echec - Regular expression is empty
chaine ANSI vide : Echec - Regular expression is empty
chaine UNICODE vide : Echec - Regular expression is empty
ANSI match : OK
UNICODE match : OK
ANSI match pas : Echec - Expression does not match with the regular expression
UNICODE match pas : Echec - Expression does not match with the regular expression
ANSI match : OK
UNICODE match : OK
ANSI match pas : Echec - Expression does not match with the regular expression
UNICODE match pas : Echec - Expression does not match with the regular expression
ANSI match : OK
UNICODE match : OK
ANSI match pas : Echec - Expression does not match with the regular expression
UNICODE match pas : Echec - Expression does not match with the regular expression
ANSI match : OK
UNICODE match : OK
ANSI match pas : Echec - Expression does not match with the regular expression
UNICODE match pas : Echec - Expression does not match with the regular expression
5. Conclusions▲
Les expressions régulières permettent de régler les problèmes d'analyse de texte et d'extraction des champs d'une manière simple et élégante. Qui n'a jamais écrit un analyseur pour extraire toutes les parties du nom complet d'un fichier (lecteur, chemin, nom du fichier, extension du fichier) ?
Par contre, il est vrai que la syntaxe d'une expression régulière n'est pas évidente au premier abord. Cela demande un effort d'apprentissage mais cet effort est très vite compensé par la souplesse et la puissance apportées.
Ce tutoriel ne fait qu'effleurer l'utilisation de la bibliothèque Boost.Regex et ne donne qu'un petit aperçu de sa puissance. Pour plus d'informations, il ne faut pas hésiter à se plonger dans la documentation officielle.
Dans le cadre professionnel, j'utilise les expressions régulières dans un programme permettant de recevoir en temps réel les messages de log d'un firewall (1000 par seconde en moyenne) et pour extraire les informations pertinentes (adresses IP source et destination, protocole, ports source et destination, message) afin de les traiter.
J'espère que ce tutoriel vous aura aussi donné l'envie d'utiliser les expressions régulières ainsi que la bibliothèque Boost.Regex.