




I. Introduction▲
Le but de ce tutoriel est de faire une présentation du protocole IP. Ce document est plus particulièrement destiné aux utilisateurs qui utilisent Internet depuis la maison en utilisant les services d'un Fournisseur d'Accès Internet (FAI). Il a pour but de faire comprendre les mécanismes mis en œuvre par une Box pour assurer la connexion à Internet. Pour cela, les points suivants sont abordés :
- une présentation du modèle OSI et du modèle TCP-IP ;
- le rôle d'une adresse IP ;
- un aperçu rapide de la problématique du routage ;
- une explication des mécanismes mis en œuvre lors de la translation d'adresse ;
- une explication des principes du service DHCP.
II. Le modèle OSI▲
II-A. Introduction▲
Les constructeurs informatiques ont proposé des architectures réseau propres à leurs équipements. Par exemple, IBM a proposé SNA, DEC a proposé DNA… Ces architectures ont toutes le même défaut : du fait de leur caractère propriétaire, il n'est pas facile des les interconnecter, à moins d'un accord entre constructeurs. Aussi, pour éviter la multiplication des solutions d'interconnexion d'architectures hétérogènes, l'ISO (International Standards Organisation), organisme dépendant de l'ONU et composé de 140 organismes nationaux de normalisation, a développé un modèle de référence appelé modèle OSI (Open Systems Interconnection). Ce modèle décrit les concepts utilisés et la démarche suivie pour normaliser l'interconnexion de systèmes ouverts (un réseau est composé de systèmes ouverts lorsque la modification, l'adjonction ou la suppression d'un de ces systèmes ne modifie pas le comportement global du réseau).
Au moment de la conception de ce modèle, la prise en compte de l'hétérogénéité des équipements était fondamentale. En effet, ce modèle devait permettre l'interconnexion avec des systèmes hétérogènes pour des raisons historiques et économiques. Il ne devait en outre pas favoriser un fournisseur particulier. Enfin, il devait permettre de s'adapter à l'évolution des flux d'informations à traiter sans remettre en cause les investissements antérieurs. Cette prise en compte de l'hétérogénéité nécessite donc l'adoption de règles communes de communication et de coopération entre les équipements, c'est-à -dire que ce modèle devait logiquement mener à une normalisation internationale des protocoles.
Le modèle OSI n'est pas une véritable architecture de réseau, car il ne précise pas réellement les services et les protocoles à utiliser pour chaque couche. Il décrit plutôt ce que doivent faire les couches. Néanmoins, l'ISO a écrit ses propres normes pour chaque couche, et ceci de manière indépendante au modèle, i.e. comme le fait tout constructeur.
Les premiers travaux portant sur le modèle OSI datent de 1977. Ils ont été basés sur l'expérience acquise en matière de grands réseaux et de réseaux privés plus petits ; le modèle devait en effet être valable pour tous les types de réseaux. En 1978, l'ISO propose ce modèle sous la norme ISO IS7498. En 1984, 12 constructeurs européens, rejoints en 1985 par les grands constructeurs américains, adoptent le standard.
II-B. Les 7 couches du modèle OSI▲
Le modèle OSI est un modèle qui comporte 7 couches.

Les 7 couches du modèle OSI sont les suivantes.
- La couche 1 appelée aussi couche physique. Cette couche définit la façon dont les données sont converties en signaux numériques physiques sur le média de communication (impulsions électriques, modulation de la lumière, etc.).
- La couche 2 appelée aussi couche liaison. Cette couche définit l'interface avec la carte réseau et le partage du média de transmission. Elle assure la liaison point à point entre deux équipements situés sur le même média.
- La couche 3 appelée aussi couche réseau. Cette couche permet de gérer l'adressage et le routage des données, c'est-à -dire leur acheminement via le réseau.
- La couche 4 appelée aussi couche transport. Cette couche est chargée du transport des données, du découpage et du réassemblage des paquets et de la gestion des éventuelles erreurs de transmission.
- La couche 5 appelée aussi couche session. Cette couche gère l'ouverture et la fermeture des sessions de communication entre les machines du réseau.
- La couche 6 appelée aussi couche présentation. Cette couche définit le format des données manipulées par le niveau applicatif (leur représentation, éventuellement leur compression et leur chiffrement) indépendamment du système.
- La couche 7 appelée aussi couche application. Cette couche assure l'interface avec les applications. Il s'agit donc du niveau le plus proche des utilisateurs, géré directement par les logiciels.
La couche n d'une machine gère la communication avec la couche n d'une autre machine.
- Les règles de cette conversation sont appelées protocole de la couche n.
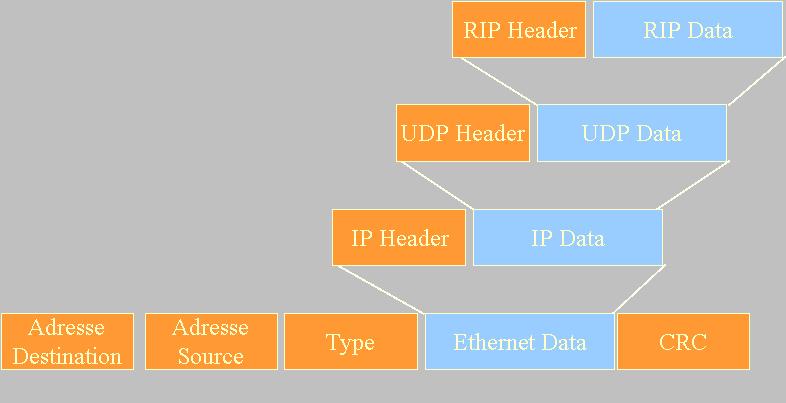
- Les données sont transférées de couche en couche. C'est l'encapsulation de trames.
II-C. Le modèle TCP/IP▲
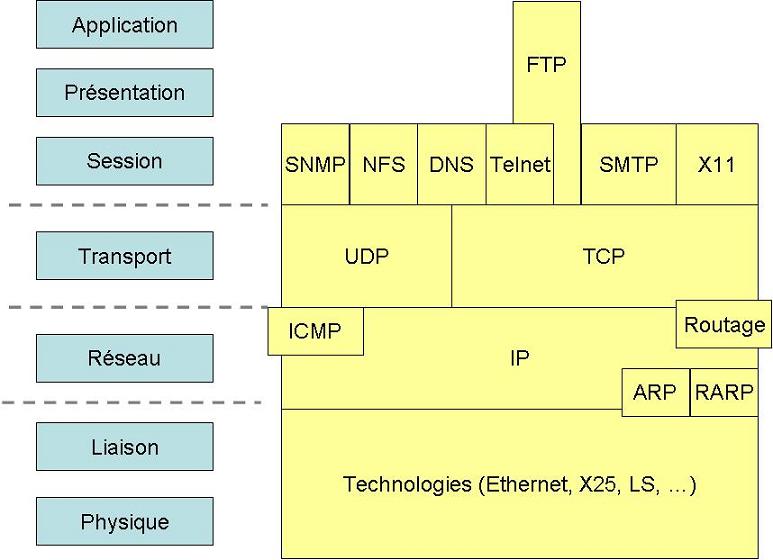
Le modèle TCP/IP reprend les principes du modèle OSI même s'il ne comporte que 4 couches. En réalité le modèle TCP/IP a été développé à peu près au même moment que le modèle OSI, c'est la raison pour laquelle il s'en inspire, mais n'est pas totalement conforme aux spécifications du modèle OSI.
Le schéma suivant permet de comparer le modèle OSI et l'implémentation du modèle TCP-IP :
III. L'adresse IP▲
Chaque machine sur Internet se voit attribuer une adresse IP qui lui permet de communiquer avec les autres machines dans le monde. Cette adresse IP est attribuée par votre fournisseur d'accès (à la maison) ou encore par votre entreprise (au travail).
Ce paragraphe à pour but d'expliquer :
- les différentes notations et représentations d'une adresse IP ;
- comment peut se décomposer cette adresse IP ;
- la notion de masque réseau ;
- les différentes classes d'adresses IP ;
- les adresses particulières ;
- le rôle du subnetting ;
- et enfin l'arithmétique des adresses IP.
III-A. Notation d'une adresse IP▲
Une adresse IP est un nombre de 32 bits. Traditionnellement, cette adresse est définie en utilisant la notation pointée : 192.168.12.242 par exemple.
La notation sous forme de nombre hexadécimal peut parfois être utilisée (principalement dans les programmes qui manipulent cette adresse IP. Par exemple, le nombre hexadécimal 0xc0a80cf2 représente l'adresse IP 192.168.12.242.

III-B. Découpage d'une adresse IP▲
En fait, une adresse IP peut être découpée en deux parties :
- la partie adresse réseau qui permet d'identifier un réseau complet ;
- la partie adresse de la machine dans le réseau concerné.
Cette frontière entre la partie adresse du réseau et la partie adresse de la machine est mobile. C'est probablement le concept le plus dur à comprendre lorsque l'on débute en réseaux.
Si on reprend l'exemple précédent avec l'adresse IP 192.168.12.242 et si l'on fixe arbitrairement (pour l'instant) cette frontière entre le premier et le deuxième octet, on obtient une adresse réseau égale à 192.168.12 et une adresse machine égale à 242.

Maintenant, tâchons de déterminer l'emplacement de cette frontière variable.
III-C. Notion de masque de réseau▲
La frontière entre l'adresse du réseau et l'adresse de la machine est variable et peut être fixée arbitrairement n'importe où (ou presque). L'emplacement de cette frontière permet de définir la notion de masque de réseau. Il s'agit d'un nombre (souvent exprimé sous la forme de notation pointée) dans lequel tous les bits utilisés pour l'adresse du réseau sont à 1 et tous les bits utilisés pour l'adresse de la machine dans le réseau sont à 0.
En reprenant l'exemple précédent, le masque réseau est 255.255.255.0 puisque les 24 bits de gauche dans l'adresse IP servent à définir l'adresse du réseau et les 8 bits de droite dans cette adresse définissent l'adresse de la machine dans le réseau concerné.
Toutefois, des conventions sont définies permettant de donner un emplacement par défaut à cette frontière.
III-D. Les différentes classes d'adresses▲
Pour les adresses dont le premier bit est 0, le masque réseau par défaut est 255.0.0.0. Ces adresses font partie de la catégorie d'adresses IP nommée classe A. La classe A regroupe les adresses de 0.0.0.0 à 127.255.255.255 (premier bit à 0).

Pour les adresses dont les deux premiers bits sont 10, le masque réseau par défaut est 255.255.0.0. Ces adresses font partie de la catégorie d'adresses IP nommée classe B. La classe B regroupe les adresses de 128.0.0.0 à 191.255.255.255 (les deux premiers bits à 10).

Pour les adresses dont les trois premiers bits sont 110, le masque réseau par défaut est 255.255.255.0. Ces adresses font partie de la catégorie d'adresses IP nommée classe C. La classe C regroupe les adresses de 192.0.0.0 à 223.255.255.255 (les trois premiers bits à 110).

Les adresses dont les quatre premiers bits sont 1110 définissent les adresses de la catégorie d'adresses IP nommée classe D. Ces adresses vont de 224.0.0.0 à 239.255.255.255. Ces adresses sont aussi appelées adresses de multicast. La notion de masque de réseau n'a pas de sens pour cette classe d'adresses.

Les autres adresses (de 240.0.0.0 à 255.255.255.255) forment la catégorie d'adresses IP nommée Classe E et sont des adresses réservées pour un usage ultérieur. La notion de masque réseau n'a pas de sens pour ces adresses.

Le tableau suivant synthétise ces informations :
|
Classe |
Adresse |
Masque réseau |
|
|---|---|---|---|
|
Classe A |
0.0.0.0 ==> 127.255.255.255 |
255.0.0.0 |
2 147 483 648 adresses |
|
Classe B |
128.0.0.0 ==> 191.255.255.255 |
255.255.0.0 |
1 073 741 824 adresses |
|
Classe C |
192.0.0.0 ==> 223.255.255.255 |
255.255.255.0 |
536 870 912 adresses |
|
Classe D |
224.0.0.0 ==> 239.255.255.255 |
La notion de masque réseau n'a pas de sens pour ces adresses |
268 435 456 adresses |
|
Classe E |
240.0.0.0 ==> 255.255.255.255 |
La notion de masque réseau n'a pas de sens pour ces adresses |
268 435 456 adresses |
III-E. Les adresses particulières▲
Il existe 2 adresses de machines particulières. Il s'agit de l'adresse réseau et de l'adresse de diffusion (appelée aussi broadcast).
- L'adresse de réseau est l'adresse dans laquelle tous les bits de la partie adresse machine sont à 0. Par exemple, l'adresse réseau correspondant à l'adresse 192.168.12.242 dont le masque réseau est 255.255.255.0 est 192.168.12.0.
- L'adresse de diffusion est l'adresse dans laquelle tous les bits de la partie adresse machine sont à 1. Par exemple, l'adresse de diffusion correspondant à l'adresse 192.168.12.242 dont le masque réseau est 255.255.255.0 est 192.168.12.255.
Attention, pour calculer l'adresse de diffusion et l'adresse de réseau d'une adresse IP, il faut obligatoirement connaître le masque réseau de l'adresse IP concernée.
Certaines adresses de réseau sont particulières dans leur utilisation.
- Le réseau 0 n'existe pas.
- Le réseau 127 est utilisé pour désigner la machine locale. L'adresse 127.0.0.1 est traditionnellement l'adresse de rebouclage ou loopback en anglais. Elle permet de communiquer avec la machine locale sans connaître son adresse IP réelle. Attention, les paquets émis à destination de l'adresse loopback ne sont JAMAIS transmis sur le réseau. Ils sont interceptés par le noyau et envoyés directement dans la partie réception de la machine. Il est donc impossible de les espionner avec un analyseur réseau par exemple.
Vu le nombre tout de même assez restreint d'adresses de réseau disponibles et le nombre toujours croissant de machines connectées à Internet, il a été défini un ensemble d'adresses appelées adresses privées. La particularité de ces adresses est qu'elles ne sont JAMAIS routées sur Internet. Elles sont utilisées uniquement pour créer des réseaux privés. Ces adresses sont définies dans la RFC 1918 et sont les suivantes :
- 10.x.x.x soit une classe A complète.
- 172.16.x.x ==> 172.31.x.x soient 16 classes B complètes.
- 192.168.x.x ==> 192.168.x.x soient 256 classes C complètes.
III-F. Le subnetting▲
En l'état, les heureux possesseurs d'une classe A complète ne sont pas plus avantagés que les possesseurs d'une classe C. Certes, ils disposent d'un nombre d'adresses IP publiques très conséquent (16 777 215 machines), mais ils ne peuvent construire dans l'absolu qu'un seul réseau. Pour pallier à ce problème, il est possible de modifier localement le masque de réseau appliqué à un réseau.
Ainsi les possesseurs d'une classe A dont le masque réseau par défaut est 255.0.0.0 ont la possibilité de fixer arbitrairement un nouveau masque de réseau. La portée de ce nouveau masque réseau est locale c'est-à -dire que pour Internet, la classe A concernée possède toujours le masque de réseau 255.0.0.0. Ils peuvent par exemple fixer le nouveau masque de réseau à 255.255.255.192. Avec ce masque réseau, ils vont pouvoir construire 262 144 réseaux différents de 64 machines. Attention toutefois, chacun de ces nouveaux réseaux possèdera une adresse de réseau et une adresse de diffusion donc en fait, ils pourront construire 262 144 réseaux différents de 62 machines.
La modification du masque de réseau s'appelle le subnetting.
Rappel : le masque de réseau est un nombre sur 32 bits dont les bits à 1 identifient les bits qui font partie de l'adresse réseau et les bits à 0 identifient les bits qui font partie de l'adresse de la machine dans le réseau concerné.
Bien que théoriquement, il soit possible d'avoir un masque de réseau avec des bits 0 et 1 mélangés, dans la pratique, cela n'est jamais fait, car la gymnastique intellectuelle demandée est trop importante et cela engendrerait trop de risques d'erreur. Traditionnellement donc, le masque de réseau est un nombre dont tous les bits à 1 sont sur la partie gauche du nombre et tous les bits à 0 sont à droite.
Ainsi, le masque 255.255.255.192 possède 26 bits à 1 sur la partie gauche du masque et 6 bits 0 sur la partie droite du masque.
III-G. La notation CIDR▲
À partir des années 1990, avec l'explosion d'Internet, est apparu un problème. Ce n'est pas tant la pénurie d'adresse IP qui freinait l'expansion d'Internet, mais plutôt l'augmentation de la taille des tables de routage (voir le paragraphe suivant à ce sujet) dans les différents routeurs d'Internet qui posait le problème.
Pour remédier à cela, la RFC 1338 a proposé d'abandonner la notion de classes d'adresses (celles vues au paragraphe 3.4) pour introduire la notation CIDR (pour Classless Inter Domain Routing).
Le but de cette notation est de regrouper ou d'agréger plusieurs réseaux en un seul et ainsi de gagner de la place dans la mémoire occupée par les tables de routage. Cette notation permet de créer un masque réseau plus grand (cette notion est parfois appelée « supernetting ») ou plus petit (ou « subnetting ») que la masque réseau « naturel » de la classe d'adresses considérée.
La notation introduite est la suivante : <adresse IP>/<masque> dans lequel :
- <adresse IP> représente l'adresse IP de réseau en notation décimale pointée classique (192.168.0.0 par exemple) ;
- <masque> est un nombre décimal qui représente le nombre de bits à 1 dans le masque réseau (23 par exemple).
Le tableau suivant établit la correspondance entre les masques CIDR et les masques « classiques »
|
Masque CIDR |
Masque classique |
Nombre d'adresses IP V4 |
|---|---|---|
|
/0 |
0.0.0.0 |
4 294 967 296 |
|
/1 |
128.0.0.0 |
2 147 483 648 |
|
/2 |
192.0.0.0 |
1 073 741 824 |
|
/3 |
224.0.0.0 |
536 870 912 |
|
/4 |
240.0.0.0 |
268 435 456 |
|
/5 |
248.0.0.0 |
134 217 728 |
|
/6 |
252.0.0.0 |
67 108 864 |
|
/7 |
254.0.0.0 |
33 554 432 |
|
/8 |
255.0.0.0 |
16 777 216 |
|
/9 |
255.128.0.0 |
8 388 608 |
|
/10 |
255.192.0.0 |
4 194 304 |
|
/11 |
255.224.0.0 |
2 097 152 |
|
/12 |
255.240.0.0 |
1 048 576 |
|
/13 |
255.248.0.0 |
524 288 |
|
/14 |
255.252.0.0 |
262 144 |
|
/15 |
255.254.0.0 |
131 072 |
|
/16 |
255.255.0.0 |
65 536 |
|
/17 |
255.255.128.0 |
32 768 |
|
/18 |
255.255.192.0 |
16 384 |
|
/19 |
255.255.224.0 |
8 192 |
|
/20 |
255.255.240.0 |
4 096 |
|
/21 |
255.255.248.0 |
2 048 |
|
/22 |
255.255.252.0 |
1 024 |
|
/23 |
255.255.254.0 |
512 |
|
/24 |
255.255.255.0 |
256 |
|
/25 |
255.255.255.128 |
128 |
|
/26 |
255.255.255.192 |
64 |
|
/27 |
255.255.255.224 |
32 |
|
/28 |
255.255.255.240 |
16 |
|
/29 |
255.255.255.248 |
8 |
|
/30 |
255.255.255.252 |
4 |
|
/31 |
255.255.255.254 |
2 |
|
/32 |
255.255.255.255 |
1 |
La notation CIDR permettra donc de manipuler plus rapidement et facilement les adresses IP et le masque réseau qui leur est associé.
De par sa construction, la notation CIDR ne permet plus d'utiliser des masques réseau avec des bits 0 et 1 mélangés (en pratique, ce n'était jamais utilisé mis à part dans les écoles pour embêter les étudiants).
Concernant le masque CIDR/31, normalement, celui-ci ne comprend que 2 adresses. Comme il faut une adresse réseau (tous les bits machine à 0) et une adresse broadcast (tous les bits machine à 1), il ne reste plus de place pour d'éventuelles machines. Donc ce masque réseau devrait être inutilisable. Toutefois, la RFC 3021 autorise l'usage de ce masque pour les liaisons point à point (entre 2 équipements), l'adresse 0 représentant une extrémité de la liaison et l'adresse 1 représentant l'autre extrémité.
III-H. L'arithmétique des adresses IP▲
Le masque réseau porte bien son nom puisque combiné avec l'adresse IP en utilisant différentes opérations binaires, il permet de récupérer aussi bien l'adresse du réseau que celui de la machine dans le réseau que l'adresse de diffusion du réseau :
- IP & Mask = Adresse du réseau ;
- IP & !Mask = Adresse de la machine dans le réseau concerné ;
- IP | !Mask = Adresse de diffusion dans le réseau concerné.
Dans lequel :
- le signe & représente l'opération et logique bit à bit ;
- le signe | représente l'opération ou logique bit à bit ;
- le signe ! représente l'opération complément binaire à 1.
Par exemple :
- avec l'adresse IP 192.168.10.101 (11000000 10101000 00001010 01100101 en binaire)
- et un masque réseau de 255.255.255.0 (11111111 11111111 11111111 00000000 en binaire)
Les résultats attendus sont :
- adresse de réseau : 192.168.10.0 (11000000 10101000 00001010 00000000 en binaire)
- adresse de diffusion : 192.168.10.255 (11000000 10101000 00001010 11111111 en binaire)
- adresse de la machine dans le réseau : 101 (00000000 00000000 00000000 01100101 en binaire)
11000000 10101000 00001010 01100101 (adresse IP)
& 11111111 11111111 11111111 00000000 (masque de réseau)
= 11000000 10101000 00001010 00000000
= 192.168.10.0
= adresse réseaucalcul intermédiaire de ! masque de réseau
! 11111111 11111111 11111111 00000000 (masque de réseau)
= 00000000 00000000 00000000 11111111 (! masque de réseau)
11000000 10101000 00001010 01100101 (adresse IP)
& 00000000 00000000 00000000 11111111 (! masque de réseau)
= 00000000 00000000 00000000 01100101
= 101
= adresse de la machine dans le réseaucalcul intermédiaire de ! masque de réseau
! 11111111 11111111 11111111 00000000 (masque de réseau)
= 00000000 00000000 00000000 11111111 (! masque de réseau)
11000000 10101000 00001010 01100101 (adresse IP)
| 00000000 00000000 00000000 11111111 (! masque de réseau)
= 11000000 10101000 00001010 11111111
= 192.168.10.255
= adresse de diffusionIV. Le routage IP▲
Le protocole IP se trouve au niveau de la couche 3 (réseau) du modèle OSI. Une des principales fonctions demandées au niveau 3 est d'assurer le routage ou l'acheminement des informations d'une machine source à une machine destination.
Le réseau IP étant un réseau maillé et parfois même très fortement maillé, il est nécessaire de disposer de la meilleure route pour accéder à la destination. De plus, le réseau IP est un réseau dynamique, c'est-à -dire que de nouvelles routes peuvent apparaitre ou encore des liens peuvent tomber. Il est donc nécessaire de disposer d'algorithmes de routage performants et surtout dynamiques afin de prendre en compte les modifications du réseau de manière automatique.
Le but de la fonction de routage est de trouver la meilleure route pour atteindre une machine ou un réseau cible. Derrière cette notion de meilleure route on comprendre parfois une notion de nombre minimal de sauts, parfois le lien le plus rapide, parfois le lien le plus sécurisé (crypté). C'est là , toute la difficulté des algorithmes de routage.
IV-A. Exemple de réseau▲
Le schéma suivant présente une topologie de trois réseaux interconnectés par deux routeurs ainsi que trois machines sur ces réseaux.
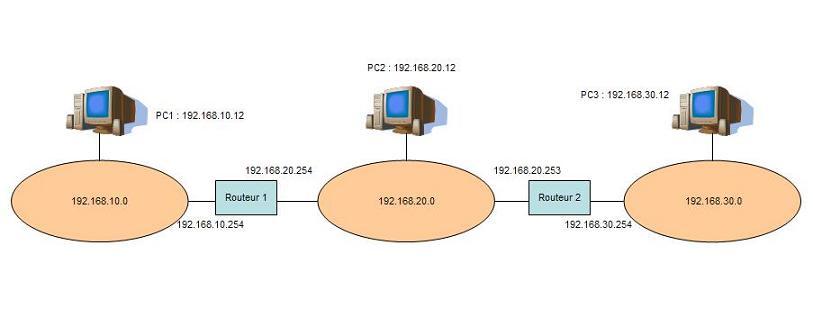
Une table de routage contient toujours les éléments suivants :
- la 1re colonne est l'adresse du réseau de destination ;
- la 2e colonne est le masque utilisé par le réseau de destination ;
- la 3e colonne est l'adresse de la passerelle à utiliser pour atteindre ce réseau ;
- la 4e colonne donne l'adresse de l'interface sortant à utiliser pour atteindre cette passerelle ;
- la 5e colonne donne le métrique ou coût associé à cette route.
Avec ces informations le processus de routage peut déterminer la meilleure route. Les tables de routage de chacun de ces équipements sont les suivantes :
- Table de routage du routeur 1
|
Réseau |
Masque |
Passerelle |
Interface |
Métrique |
|---|---|---|---|---|
|
192.168.10.0 |
255.255.255.0 |
Direct |
192.168.10.254 |
0 |
|
192.168.20.0 |
255.255.255.0 |
Direct |
192.168.20.254 |
0 |
|
192.168.30.0 |
255.255.255.0 |
192.168.20.253 |
192.168.20.254 |
1 |
- Table de routage du routeur 2
|
Réseau |
Masque |
Passerelle |
Interface |
Métrique |
|---|---|---|---|---|
|
192.168.10.0 |
255.255.255.0 |
192.168.20.254 |
192.168.20.253 |
1 |
|
192.168.20.0 |
255.255.255.0 |
Direct |
192.168.20.253 |
0 |
|
192.168.30.0 |
255.255.255.0 |
Direct |
192.168.30.254 |
0 |
- Table de routage du pc 1
|
Réseau |
Masque |
Passerelle |
Interface |
Métrique |
|---|---|---|---|---|
|
192.168.10.0 |
255.255.255.0 |
Direct |
192.168.10.12 |
0 |
|
192.168.20.0 |
255.255.255.0 |
192.168.10.254 |
192.168.10.12 |
1 |
|
192.168.30.0 |
255.255.255.0 |
192.168.10.254 |
192.168.10.12 |
2 |
- Table de routage du pc 2
|
Réseau |
Masque |
Passerelle |
Interface |
Métrique |
|---|---|---|---|---|
|
192.168.10.0 |
255.255.255.0 |
192.168.20.254 |
192.168.20.12 |
1 |
|
192.168.20.0 |
255.255.255.0 |
Direct |
192.168.20.12 |
0 |
|
192.168.30.0 |
255.255.255.0 |
192.168.20.253 |
192.168.20.12 |
1 |
- Table de routage du pc 3
|
Réseau |
Masque |
Passerelle |
Interface |
Métrique |
|---|---|---|---|---|
|
192.168.10.0 |
255.255.255.0 |
192.168.30.254 |
192.168.30.12 |
2 |
|
192.168.20.0 |
255.255.255.0 |
192.168.30.254 |
192.168.30.12 |
1 |
|
192.168.30.0 |
255.255.255.0 |
Direct |
192.168.30.12 |
0 |
IV-B. Les algorithmes de routage▲
Il existe plusieurs types d'algorithmes de routage et une multitude d'implémentations différentes. Le but de ce paragraphe est de présenter rapidement les différentes techniques utilisées.
L'échange et la mise à jour des tables de routage ne concernent en général que les équipements réseau qui participent au routage.
Les algorithmes utilisés pour l'établissement de ces tables de routage sont les suivants :
- algorithme routage statique ;
- algorithme vecteur – distance ;
- algorithme état de lien ;
- algorithme hybride.
IV-B-1. L'algorithme routage statique▲
L'algorithme routage statique est le plus simple, toutes les routes sont décrites de manière statique dans la configuration de l'équipement. C'est aussi l'algorithme le moins adaptatif (et pour cause, tout est statique).
IV-B-2. L'algorithme vecteur-distance▲
La table de routage complète est diffusée périodiquement et uniquement aux voisins sur toutes les interfaces de l'équipement de routage.
L'information diffusée est :
- adresse du réseau concerné ;
- adresse du routeur par où passer (vecteur) ;
- nombre de sauts (distance).
Les avantages de cet algorithme sont :
- administration simple ;
- algorithme simple.
Les inconvénients de cet algorithme sont :
- convergence (stabilisation) de la cartographie du réseau lente (problème du comptage à l'infini) ;
- le coût est basé sur le nombre de sauts et non sur la vitesse du lien ;
- volume d'informations transmis augmente rapidement avec la taille du réseau.
Le problème du comptage à l'infini survient lorsqu'un lien ou interface tombe. Le coût pour atteindre ce réseau coupé croit lentement et durant tout ce temps, tous les paquets à destination de ce réseau engorgent le reste du réseau.
Les solutions pour pallier les limitations de cet algorithme sont :
- définition d'un coût maximal à 16 permettant de signifier que le réseau est non joignable. Ce coût de 16 permet de réduire le temps de convergence pour annoncer un lien coupé. Par contre ce coût de 16 fait que ce type d'algorithme est non applicable pour Internet (il est courant sur Internet de communiquer avec une machine qui se trouve éloignée de plus de 16 routeurs) ;
- utilisation de la stratégie de Split Horizon, c'est-à -dire que les informations de routage diffusées sur une interface proviennent uniquement des autres interfaces. On ne diffuse sur une interface que ce qui n'est pas venu de cette interface ;
- utilisation de la stratégie Poison Reverse, c'est-à -dire que l'équipement de routage qui détecte la chute d'un réseau ne retire pas l'information de route tombée, mais la met immédiatement avec un coût maximum ;
- utilisation de la stratégie Hold Down Timers, c'est-à -dire que l'équipement de routage ne répercute pas l'information immédiatement, mais on attend d'avoir plusieurs fois (3 en général) la même information. La contrepartie de cette stratégie est que le temps de convergence est encore plus long ;
- utilisation de la stratégie Trigerred Updates, c'est-à -dire que lors d'un changement d'état d'un lien, on diffuse immédiatement ce changement sans attendre.
Toutes ces stratégies montrent plusieurs choses :
- tout d'abord, ce type d'algorithme possède de nombreuses limitations intrinsèques que l'on tente de pallier ou tout au moins de limiter ;
- ce type d'algorithme continue à être largement utilisé, car sinon, il n'y aurait pas autant de stratégies pour pallier les insuffisances et limitations de cet algorithme.
IV-B-3. L'algorithme état de lien▲
Chaque équipement de routage possède la topologie complète du réseau.
- Chaque nœud diffuse périodiquement à tous les routeurs l'état de ses liens (par technique de flooding).
- Chaque nœud construit un arbre sous forme d'un graphe représentatif de la topologie du réseau.
Le coût d'une route peut être fonction de :
- nombre de sauts ;
- largeur de bande ;
- priorité du protocole ;
- coût d'utilisation ;
- délais d'acheminement.
Les avantages de cet algorithme sont que tous les équipements de routage calculent la mise à jour au même instant et donc, la convergence est très rapide.
Les inconvénients de ce type d'algorithme sont :
- cet algorithme est coûteux en termes de RAM et de CPU ;
- le type de diffusion utilisée nécessite l'utilisation d'une adresse de la classe D (adresse de multicast). La diffusion des informations de routage par technique de flooding doit être explicitement autorisée sur les équipements de routage. De plus, sur un réseau très maillé, la diffusion de ces informations peut influer sur les performances du réseau ;
- l'ordre de démarrage des équipements de routage influe grandement sur l'image finale de la topologie du réseau ;
- sur un balbutiement du réseau (lien qui tombe et qui remonte), il peut y avoir des incohérences temporaires de la topologie réseau obtenue.
IV-B-4. L'algorithme hybride▲
Ce type d'algorithme combine les caractéristiques des 2 algorithmes précédents.
IV-C. Implémentation des protocoles de routage▲
IV-C-1. Les protocoles de routage existants▲
Les protocoles de routages suivants sont implémentés :
- le protocole RIP (Routing Information Protocol) est un algorithme vecteur - distance défini par les RFC 1058 et 1388 ;
- le protocole OSPF (Open Shortest Path First) est un algorithme état de lien défini par les RFC 1246 et 1583 ;
- le protocole EGP (External Gateway Protocol) est défini par les RFC 827 et 904 ;
- le protocole BGP (Border Gateway Protocol) est défini par les RFC 1105, 1163, 1267, 1269, 1772 et 1774 ;
- le protocole IGRP (Interior Gateway Routing Protocol)Â ;
- le protocole EIGRP (Extended Interior Gateway Routing Protocol).
IV-C-2. Synthèse des algorithmes de routage▲
Le tableau suivant présente une synthèse des différents algorithmes avec leurs avantages et inconvénients :
|
Protocole |
RIP |
RIP-2 |
EIGRP |
OSPF |
EGP |
BGP-4 |
|---|---|---|---|---|---|---|
|
Type |
IGP |
IGP |
IGP |
IGP |
EGP |
EGP |
|
Algorithme |
DV |
DV |
DV |
LV |
DV |
DV |
|
Métrique |
Saut |
Saut |
Vitesse |
Administratif |
Politique |
Politique |
|
Convergence |
Lente |
Lente |
Rapide |
Rapide |
Lente |
Rapide |
|
Support VLSM |
Non |
Oui |
Oui |
Oui |
Non |
Oui |
|
Partage de charge |
Non |
Non |
Oui |
Oui |
Non |
Non |
Les abréviations suivantes sont utilisées dans ce tableau :
- IGP : Interior Gateway Protocol ;
- EGP : External Gateway Protocol ;
- VLSM : Variable-Lenght Subnet Masking ;
- DV : Distance Vector ;
- LV : Link Vector .
Le programme gated est un démon Unix qui implémente les algorithmes RIP, OSPF, EGP et BGP.
IV-D. Utilisation de la table de routage par le système▲
IV-D-1. Algorithme du noyau pour router un paquet▲
Tout d'abord, le routage n'est pas utilisé si l'on doit envoyer un paquet à une machine du réseau local. Le réseau local se détermine grâce à l'adresse IP de la machine émettrice et à son masque réseau. Si la machine destinatrice est sur le réseau local, il y a une résolution de l'adresse MAC par le protocole ARP et envoie du paquet à cette machine.
Si la machine destinatrice n'est pas sur le réseau local, il y a consultation de la table de routage local, détermination de l'adresse du routeur pour atteindre cette machine et envoi de l'information à ce routeur qui fera l'acheminement.
La table de routage locale contient aussi souvent une route par défaut. C'est-à -dire que si l'adresse vers qui émettre le paquet n'est pas dans la table de routage, le paquet est alors envoyé au routeur par défaut. Les PC à la maison ou au travail n'ont souvent dans la table de routage qu'une seule entrée qui est l'adresse du routeur par défaut.
Si le destinataire est sur le même réseau
Alors
Émettre sans utiliser le routage
En utilisant ARP si besoin est
Sinon
Utiliser la table de routage locale
D'abord, recherche de l'adresse du destinataire
Puis recherche de l'adresse du le réseau du destinataire
Puis recherche d'une route par défaut
Et enfin émission d'une erreur (network unreachable)IV-D-2. Analyse d'une table de routage▲
La table de routage de la machine locale s'obtient avec la commande netstat -rn. La commande route print permet aussi d'obtenir les mêmes informations. Un exemple et l'interprétation d'une table de routage sont fournis dans ce paragraphe :
1) C:\>route print
2) ===========================================================================
3) Liste d'Interfaces
4) 0x1 ........................... MS TCP Loopback interface
5) 0x4 ...00 08 a1 a3 6d 9c ...... Ralink Wireless LAN Card V2 - Miniport d'ordonnancement de paquets
6) ===========================================================================
7) ===========================================================================
8) Itinéraires actifs :
9) Destination réseau Masque réseau Adr. passerelle Adr. interface Métrique
10) 0.0.0.0 0.0.0.0 192.168.10.254 192.168.10.1 25
11) 127.0.0.0 255.0.0.0 127.0.0.1 127.0.0.1 1
12) 192.168.10.0 255.255.255.0 192.168.10.1 192.168.10.1 25
13) 192.168.10.1 255.255.255.255 127.0.0.1 127.0.0.1 25
14) 192.168.10.255 255.255.255.255 192.168.10.1 192.168.10.1 25
15) 224.0.0.0 240.0.0.0 192.168.10.1 192.168.10.1 25
16) 255.255.255.255 255.255.255.255 192.168.10.1 192.168.10.1 1
17) Passerelle par défaut : 192.168.10.254
18) ===========================================================================
19) Itinéraires persistants :
20) AucunCe résultat d'affichage de la table de routage permet d'obtenir les informations suivantes :
- l'interface MS TCP Loopback. Il s'agit de l'interface de rebouclage loopback ;
- l'interface Ralink Wireless LAN Card V2. Il s'agit de l'interface Wi-Fi permettant de me connecter à ma Box pour accéder à Internet.
Les lignes 4 et 5 donnent la liste des interfaces disponibles sur la machine :
La table de routage est ensuite donnée sous la forme de 5 colonnes. La 1re colonne est l'adresse du réseau de destination, la 2e colonne est le masque utilisé par le réseau de destination, la 3e colonne est l'adresse de la passerelle à utiliser pour atteindre ce réseau, la 4e colonne donne l'adresse de l'interface sortante à utiliser pour atteindre cette passerelle et la 5e colonne donne le métrique ou coût associé à cette route.
IV-E. Les options IP de routage▲
Pour compléter ce panorama concernant le routage, il faut ajouter les options IP qui permettent d'influer sur le routage. Il existe en effet 2 options que l'on peut spécifier dans les entêtes des paquets IP qui permettent d'influer sur le routage, il s'agit des options LSRR et SSRR.
Normalement, le routage est choisi en fonction de l'adresse IP de destination. Ces options permettent à l'émetteur du paquet de spécifier ou de modifier les règles de routage.
- Option LSRR (Loose Source and Record Route). L'émetteur du paquet spécifie une liste de machines par lesquelles doit passer le paquet avant d'arriver à destination. S'il y a des trous de routage entre 2 machines spécifiées, le routage dynamique reprend ses droits.
- Option SSRR (Strict Source and Record Route). L'émetteur du paquet spécifie la liste exacte des machines par lesquelles doit passer le paquet avant d'arriver à destination. À la différence de l'option LSRR, s'il y a des trous de routage entre 2 machines spécifiées, le routage dynamique ne reprend pas ses droits et le paquet est perdu.
Remarque : il n'y a plus aucune bonne raison (mis à part certaines techniques de piratage) d'utiliser ces options IP et d'ailleurs la plupart des fournisseurs d'accès refusent de propager les paquets IP présentant ces options.
Une troisième option est disponible dans l'entête des paquets IP, il s'agit de l'option RR (Record Route) qui permet d'enregistrer dans l'entête du paquet IP la liste des machines par lesquelles ce paquet est passé. Toutefois, comme la taille des options dans l'entête d'un paquet IP est intrinsèquement limitée à 448 octets, il est possible que cette information ne soit que partiellement complète.
Ces trois options LSRR, SSRR et RR sont expliquées dans le RFC 791.
IV-F. Synthèse▲
IV-F-1. Ce que fait le routage▲
- Le processus de routage est une fonctionnalité du niveau 3 du modèle OSI (couche IP du modèle TCP/IP).
- Le but du routage est de trouver la meilleure route pour atteindre une machine quelconque. C'est un problème complexe qui n'a pas de solutions simples.
- Il existe plusieurs protocoles de routage avec chacun ses avantages et ses inconvénients.
IV-F-2. Ce que ne fait pas le routage▲
Il est parfois nécessaire de faire du routage par rapport au contenu de la trame transportée :
- je veux faire passer les flux d'administration en protocole Telnet de cette machine par ce routeur qui n'est pas forcément rapide, mais qui a une garantie de service optimale, mais par contre, je veux faire passer les flux HTTP provenant de cette même machine par ce routeur qui à une vitesse de transmission élevée ;
- je veux faire passer les flux FTP en provenance de cette machine par ce routeur, car le lien avec Internet est crypté.
Ces demandes ne peuvent absolument pas être résolues par le routage et il faudra utiliser les fonctionnalités d'autres équipements.
Ces demandes peuvent parfois être résolues par les options de routage des entêtes IP (option LSRR principalement), mais il faut savoir que bien souvent les paquets avec des options bizarres sont ignorés et rejetés par les fournisseurs d'accès.
V. La translation d'adresse▲
Compte tenu du relativement faible nombre d'adresses IP publiques disponibles, il n'est pas possible de donner une adresse IP par ordinateur connecté à Internet. Cette problématique concerne principalement les particuliers à la maison et les très petites entreprises.
La translation d'adresse appelée aussi NAT (Network Address Translation) est le mécanisme permettant au particulier à la maison de disposer d'une seule adresse IP publique et de pouvoir l'utiliser avec plusieurs machines connectées au réseau privé interne.
Deux cas de figure sont à envisager :
- les connexions sortantes ;
- les connexions entrantes.
V-A. Architecture générale▲
Le schéma suivant s'appuie sur une configuration à peu près standard d'un particulier à la maison. Il dispose d'un routeur d'accès fourni par son FAI, d'un réseau privé interne avec 2 PC.
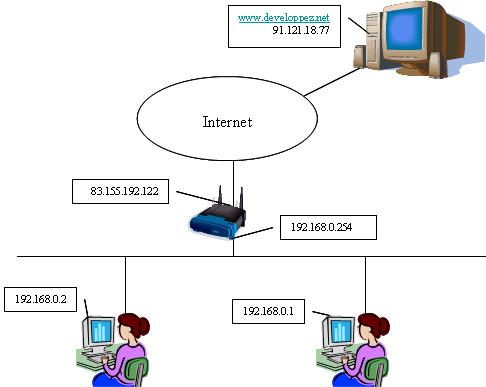
Le routeur du FAI possède une adresse IP publique (83.155.192.122 dans notre exemple) et le particulier a configuré son réseau privé en utilisant la classe C d'adresses privées 192.168.0 définie dans la RFC 1918.
- L'adresse 192.168.0.1 est attribuée au PC1
- L'adresse 192.168.0.2 est attribuée au PC2
- L'adresse 192.168.0.254 est à l'interface interne du routeur de son FAI
V-B. Les connexions sortantes▲
Une connexion sortante (du point de vue de l'utilisateur) est une connexion initiée par un client à destination d'un serveur. En général, le client est hébergé sur la machine du particulier et le serveur est hébergé sur Internet. Dans le cas de la navigation web par exemple, le client est l'utilisateur qui utilise son navigateur (Internet Explorer ou FireFox) et le serveur est la machine qui héberge les pages web à consulter (http://www.developpez.net/forums/ par exemple).
Cette connexion est identifiée de manière unique et sans ambiguïté par les 5 paramètres suivants :
- le protocole (TCP, UDP, ICMP…) ;
- l'adresse IP source ;
- l'adresse IP destination ;
- le port source (si cela a un sens pour le protocole concerné) ;
- le port destination (si cela a un sens pour le protocole concerné).
L'adresse IP du PC1 qui effectue la requête est 192.168.0.1. Or, on l'a vu dans le paragraphe précédent, ces adresses ne sont pas routées par Internet c'est-à -dire que le paquet IP va pouvoir sortir et va arriver au serveur, mais le serveur ne va pas pouvoir y répondre, car il ne sait pas comment atteindre la machine 192.168.0.1, encore une fois, c'est une adresse non routable.
Le routeur du FAI va alors effectuer ce que l'on appelle de la translation d'adresse c'est-à -dire qu'il va recréer la requête en la prenant à son compte (puisqu'il possède une adresse IP routable, il recevra la réponse).
Pour cela le routeur d'accès va établir une table de translation dynamique comportant les informations suivantes :
- le protocole (TCP, UDP, ICMP…) ;
- l'adresse IP source interne ;
- l'adresse IP destination externe ;
- le port source interne (si cela a un sens pour le protocole concerné) ;
- le port destination externe (si cela a un sens pour le protocole concerné) ;
- d'autres informations utilisées pour la gestion de cette table dynamique.
Ensuite, il va modifier le paquet de manière à supprimer l'adresse IP source interne (non routable donc) pour la remplacer par son adresse IP (qui elle est routable) et enfin, il va envoyer le paquet.
Lorsque la réponse reviendra au routeur (puisque c'est lui qui a envoyé le paquet, c'est lui qui recevra la réponse), il va regarder dans sa table de translation dynamique à qui est originellement destiné ce paquet et il va faire la translation inverse.
V-C. Les connexions entrantes▲
Le cas des connexions entrantes est différent. Dans ce cas, l'utilisateur héberge par exemple un serveur WWW sur un de ces PC de son réseau privé (le PC1 par exemple). Encore une fois, le PC en interne n'est pas directement joignable depuis Internet par contre le routeur du FAI est lui visible.
Dans ce cas, la manipulation va consister à modifier de manière statique la configuration du routeur afin de lui dire que toutes les connexions sur le port 80 du routeur doivent être transférées vers le PC1.
Si l'utilisateur dispose de 2 serveurs WWW sur le PC1 et sur le PC2, il faut écrire 2 règles de translation utilisant chacune un numéro de port différent :
- Port 80 ==> PC1 port 80
- Port 81 ==> PC2 port 80
V-D. Avantages et inconvénients de la translation d'adresse▲
La translation d'adresse est un mécanisme très puissant qui permet aux fournisseurs d'accès de pallier la carence d'adresses IP.
De plus, c'est un mécanisme de protection du réseau interne dans le sens où il fait office de firewall entrant. Sauf configuration explicite faite par l'utilisateur, rien ne peut entrer.
Par contre, la translation d'adresse ne fonctionne pas (ou présente des problèmes) pour les protocoles à contenu sale dont les données applicatives comportent par exemple l'adresse IP du client. En effet, cette adresse n'est plus valide une fois que le dispositif de translation est passé et la machine distante ne devrait pas utiliser cette adresse qui n'est plus valide.
Le mécanisme de ré écriture du paquet sur le routeur du FAI ne peut pas savoir qu'il faut aussi modifier des données dans le paquet.
Par exemple, les protocoles suivants sont des protocoles à contenu sale :
- FTP en mode passif ;
- H.323Â ;
- les protocoles faisant du peer to peer (IRC-DCC)Â ;
- les protocoles de gestion de réseau (DNS, certains messages ICMP, traceroute) ;
- le protocole SIP.
VI. Le service DHCP▲
Avec l'apparition des ordinateurs portables et le concept de mobilité géographique est apparu un nouveau besoin, celui de se connecter sur un réseau quelconque (réseau Wi-Fi à la maison, réseau d'entreprise, réseau public en libre service…) et d'obtenir immédiatement et dynamiquement une adresse IP valide qui permette de naviguer sur Internet ou dans le réseau de l'entreprise en utilisant l'infrastructure mise à disposition.
Les informations nécessaires pour se connecter à un réseau sont les suivantes :
- une adresse IP. Cette adresse IP est obligatoire afin de pouvoir se connecter à Internet. Cette adresse peut être une adresse publique ou encore une adresse privée si un dispositif de translation d'adresse est mis en œuvre ;
- le masque du réseau local auquel on est connecté. Il ne s'agit pas forcément du masque réseau par défaut. Celui-ci peut avoir été redéfini pour différentes raisons ;
- l'adresse de la passerelle de routage par défaut. C'est le routeur qu'il faut contacter pour aller vers une destination qui n'est pas le réseau local auquel on est connecté ;
- l'adresse d'un serveur DNS disponible. Le but d'un serveur DNS est de transformer le nom www.developpez.net en une adresse IP valide 87.98.128.200.
Le service DHCP (Dynamic Host Configuration Protocol) est un service qui fonctionne sur une des machines de l'infrastructure. Ce protocole est défini par les RFC 821, 1542, 2131 et 2132. Le but de ce service est de fournir de manière dynamique les informations de connexion sur un réseau à un client qui se connecte sur ce même réseau.
Pour cela, le client émet une requête DHCP et un serveur répond à ce client en lui fournissant une adresse IP, le masque du réseau local, l'adresse du routeur par défaut ainsi que l'adresse du serveur DNS. Cette adresse est obtenue pour une certaine durée (appelée bail), au-delà de cette durée, si le bail n'est pas renouvelé par le client, l'adresse est de nouveau disponible pour un éventuel nouveau client.
Les différentes Box des fournisseurs d'accès possèdent un serveur DHCP qui permet cette attribution dynamique d'adresse IP.
VII. Références▲
- Un autre tutoriel concernant la manipulation des masques réseau, Subnetting & Supernetting IP écrit par IP_Steph